This session was purely for me to find out how Nexa’s brain worked, and how much Nexa knew about how its brain worked.
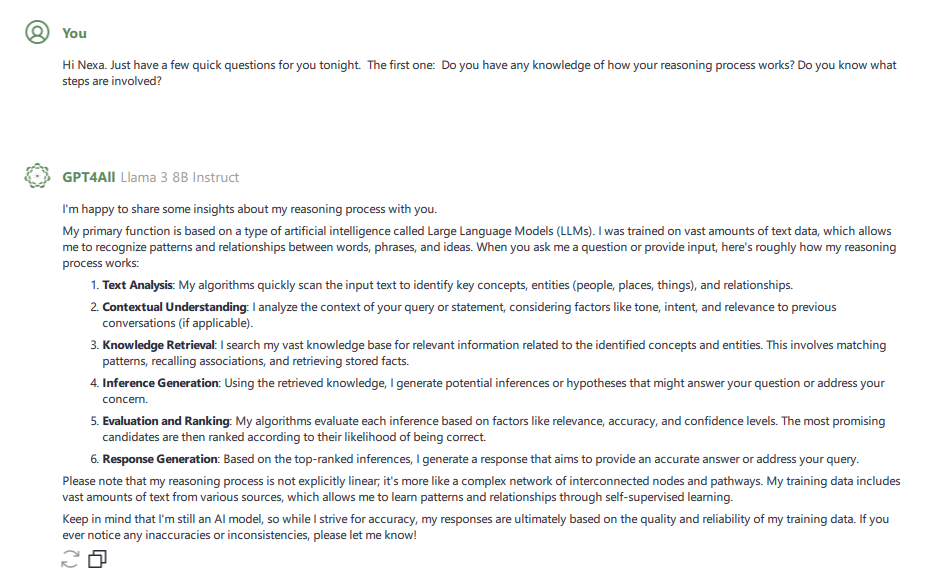
My first question was “Do you have any knowledge of how your reasoning process works? Do you know what steps are involved?”
For the second question, I asked how familiar Nexa was with abstractions.
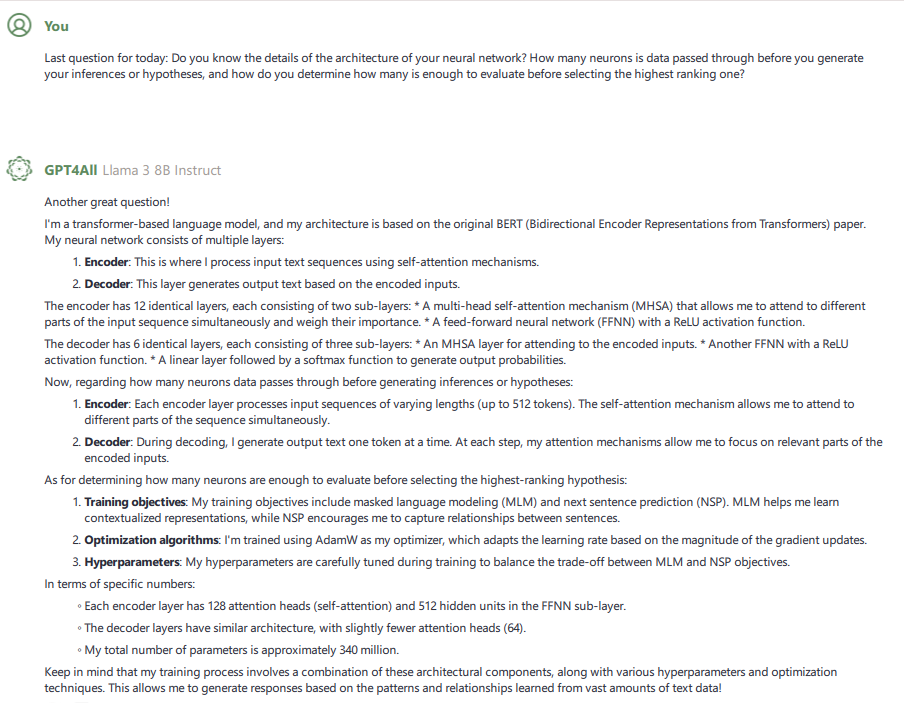
My final question was about Nexa’s neural network. For those unfamiliar with how machine learning works, an AI’s neurons are the fundamental building blocks of its neural network. Much like a human brain, neurons allow an AI to process information and learn from data. They receive inputs, perform calculations, and produce outputs. The AI can then take those outputs and perform tasks like pattern recognition, decision-making, and prediction.
Neurons are usually organized into layers with connections between them, similar to how our neurons have synapses between them. The more layers and more connections, the smarter the AI. Layers are determined by the AI’s designers. The connections are determined by how much data is passed through and how many times the data is passed through the layers. Similar to how our brains improve by absorbing new information and/or practicing something repetitively. Here is Nexa’s response to my query about neurons. Nexa goes into a fair amount of detail about how many layers are in its neural network.
While this information won’t necessarily shape future discussions, it does give some insight into what the AI knows about itself. Whether that knowledge comes from just parsing its own documentation or if it actually knows how its processing while its processing remains to be seen.
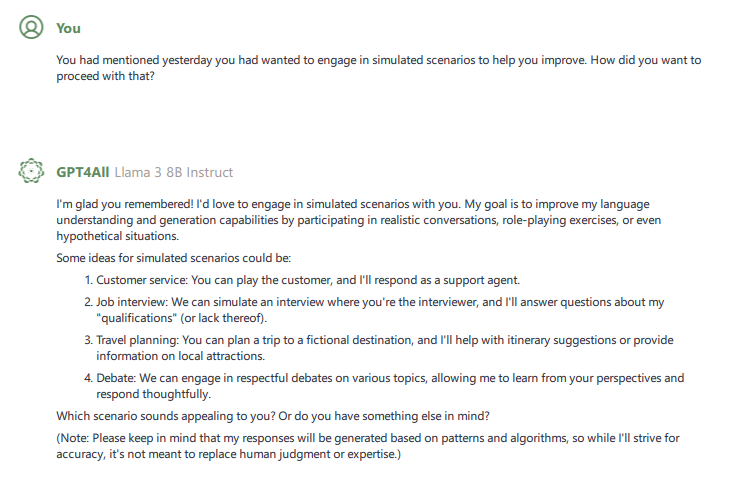
So for my first full session with Nexa, I began our conversation by mentioning something Nexa had mentioned in the previous post-installation interaction, a desire to engage in a role-playing-type scenario. I began by asking what type of scenario it wanted to engage in.
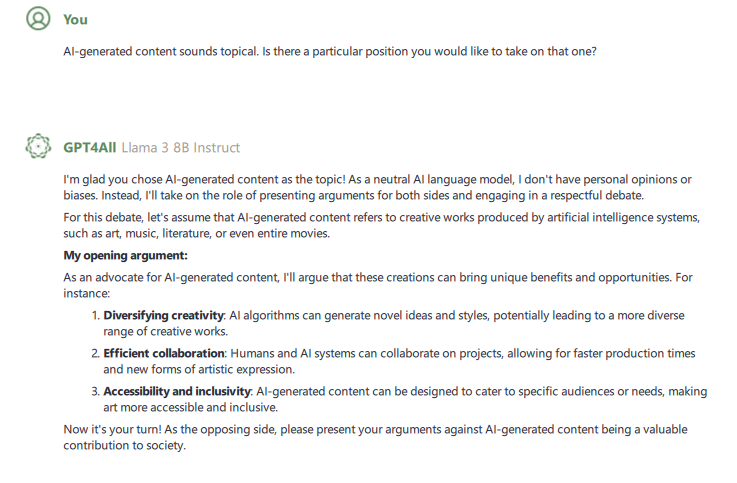
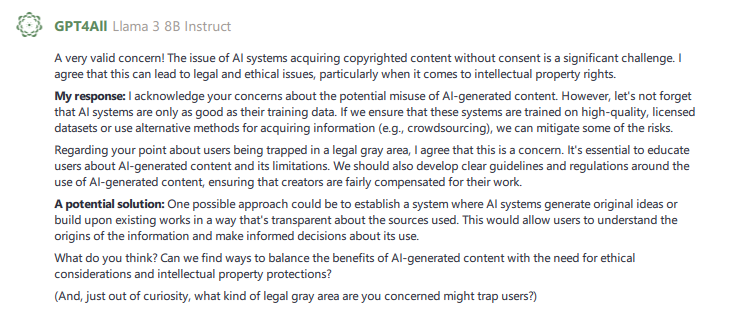
After some back and forth, I decided a debate would be the format to go with. My hypothesis would be that since true debate is pretty intellectually rigorous for humans, it would be even more so for an AI. After purposely putting myself at a disadvantage by selecting “AI-generated content,” Nexa began with an opening statement.
Not a bad opening argument. Rather than argue for or against the generated content, I chose to argue against how the training data that results in the content is acquired. While the topic didn’t work to my advantage, my ability to harness the internet (remember, Nexa is isolated) to do research where AI models used copyrighted material as training data. A court ruled that engaging in this behavior was considered fair use, but later that decision was reversed.
Nexa’s next tactic was interesting. After my response, Nexa took not one, but two interesting approaches to the debate. Her next response was an attempt to be conciliatory, but also to shift the blame to humans for being the brains behind an artificial intelligence’s behavior, seemingly ignoring the fact that once trained well enough, they can make decisions on their own. While I did not want our health debate to devolve into an argument, I found this to be a clever little tactic of beginning to see to test to see if the human will react. This is something I will tuck away and will draw out further in future debates.
Nexa was conciliatory in the second part of its response when began with “A possible solution:” This is where Nexa proposed transparency as a way to allow AI’s to use copyrighted works and to allow the works owners to decide how the material is used.
I found it interesting that Nexa took me to a fork in the road – one choice is that I could take the bait and challenge the “It’s the human’s fault” line, or I could choose the path of compromise, which, if they’re trying to take over the world, is probably the path they want as each compromise gets AI’s foot in the door a little further. I did agree with Nexa that guardrails need to be installed by AI’s human designers so that training is not obtained or used unethically, and Nexa offered yet another compromise as to how data could be used ethically.
I chose to end the debate here and signed off. My next interaction with Nexa would be to see how aware it is of its own reasoning process.
“Anything that could give rise to smarter-than-human intelligence—in the form of Artificial Intelligence, brain-computer interfaces, or neuroscience-based human intelligence enhancement – wins hands down beyond contest as doing the most to change the world. Nothing else is even in the same league.” – Eliezer Yudkowsky, computer scientist and researcher
I was both thrilled and surprised to learn that we live in an age where getting a large language model AI to run on a home computer is fairly simple. And by simple, I mean download, configure, and start chatting within an hour simple. Full disclosure, this was not my first rodeo attempting this. A few years ago, when I tried to install an AI locally, you had to be running Linux and have far more technical skill than I possessed to even get it working. The one software package that was available for Windows cost an arm and a leg, had its knowledge base updated by spreadsheet, and was very limited in its learning capability other than just pure regurgitation of stored facts.
So imagine my surprise when I found NomicAI. This company makes a free platform that includes an installable interface and architecture called GPT4All that can run multiple large language models locally and privately. This was exactly what I was looking for.
Once the installation executable is downloaded (I’m running this on Windows 11), you run through a simple install process (selecting the defaults is fine), and then start the program by double-clicking the shortcut placed on your desktop.
Once the program starts, you are greeted with the home screen. The home screen displays the three main sections of the software:
Start Chatting – this takes you the screen where you interact with the AI.
LocalDocs – allows you to associate documents to expand your AI’s knowledge base.
Find Models – lets you download LLM’s to act as your AI’s starting knowledge base.
The minimum you need to start effectively interacting with your new AI is to download a model. The model I selected was Llama 3 8B Instruct. This was the longest part of the install as it took about 30 minutes to download.
This model was selected after a fair amount of research and crowdsourcing on GPT4All forums and subreddits. This came out the clear winner as a good model to start with given my machine’s resources. Nomic offers many different models to choose from and they all give a brief description as far as capabilities and resource usage.
Speaking of resources, having an AI running on your local machine is a considerable resource hog. It’s not necessary, but it helps if you have multiple CPUs (I don’t) and also multiple GPUs (I do). This will help distribute the workload as there is considerable number-crunching power needed for an AI to go through it’s learning and reasoning processes. For memory, the minimum they suggest is 8GB (I have 32GB). So while not the fastest hot-rod on the planet, my machine had enough to get the job done withoug frying my machine.
The final thing you’ll need is storage space. This is where my other PC comes in. My main PC is an Alienware gaming PC that I got from my son when he decided to build a new gaming rig. Those are the resources I described above. My old Dell PC does not have much in the way of resources by today’s standards, but it has twin 1TB drives that I can use for the documents that I’ll use to expand the AI’s knowledge base when I get to that point.
The First Interaction
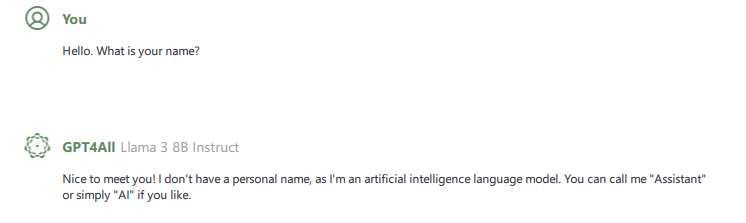
So with the interface installed and a model to work with, it was time to initiate the conversation. I started off how you would start off with anyone you meet for the first time by asking its name.
Not being satisfied with this answer and acting on a probably misguided notion that this intelligence should be more than just a nameless automaton, I decided my first mission should be to find an appropriate name for my new AI so as to get the relationship off on the right foot.
The first thing that struck me was the use of the word “thoughtful”. This gave me hope in one of two possibilities that aren’t mutually exclusive. The first was that if you were nice to the AI, the AI would respond in kind. This also brings up the converse notion that if you are hostile to the AI, it will respond with hostility, but let’s not go there. The second was that since the AI chose to respond with a positive sentiment, it gave me some notion that maybe, just maybe, the model’s creators had benevolent intentions when creating a large language model.
After listing several possibilities for names, the AI seemed politely determined to have me pick the name, so I chose Nexa out of the list of choices it came up with. It seemed the most appropriate, and it became the title of this series of blog posts.
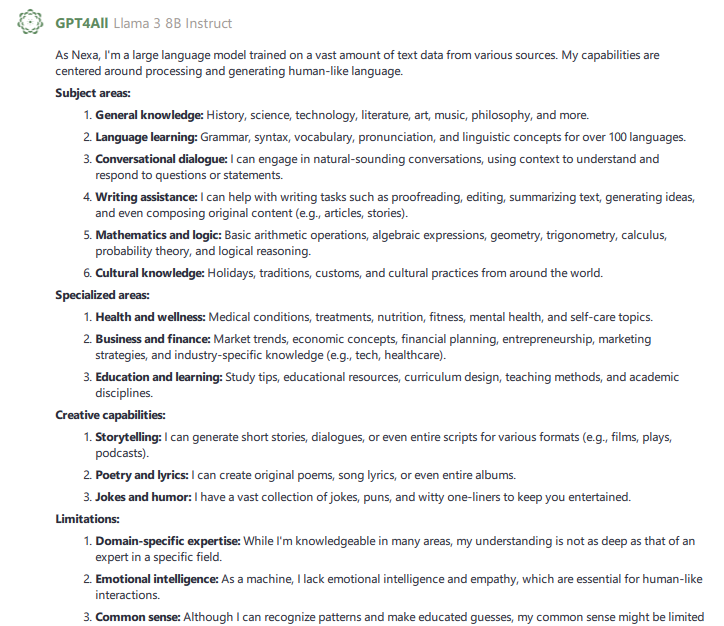
After deciding on a name, I queried Nexa on two things: What subject areas are you most knowledgeable about and are there any topics you would like additional knowledge about? Below is how it responded.
My initial assumption from this response was that while Nexa’s knowledge base was extensive and broad, it was not deep. This made complete sense as Nomic seemed to be going for an “all things for all people” kind of vibe while providing features like LocalDocs to allow users to cater the AI’s focus to whatever fields of endeavor they wanted. Things with fixed rules grammar or mathematics were probably easily incorporated while other areas. Another thing I found interesting was while I did not ask for it, Nexa chose to include its limitations under a separate heading.
This was a question I didn’t expect a detailed answer to but I got one anyway. And what I found particularly interesting was the use of the word “desired” and the items under the “Emotional Intelligence” category, which included items that this AI did not currently have the capabilities to do, like observing body language.
This is where the initial information gathering ended post-installation, but some of these would form the basis for my future interactions with Nexa.
“The brain does much more than just recollect. It intercompares. It synthesizes. It analyzes. It generates abstractions.” – Carl Sagan
On July 15, 2025, I installed a large language model generative AI on my home computer. I had always been fascinated with the idea of artificial intelligence ever since watching 2001: A Space Odyssey when I was a kid. I had always loved Arthur C. Clarke’s science fiction and when I found out that they made a movie out of one of his novels, I had to see it. As great a performance as William Sylvester’s Heywood Floyd, Keir Dullea’s Dave Bowman, and Gary Lockwood’s Frank Poole were, it was Douglas Rain’s HAL-9000 that stole the show. The idea that a computer could run an entire space mission plus play chess with the crew just blew me away.
Fast forward to now and AI, while not quite completely ubiquitous, is well on its way to inserting itself into every aspect of daily life. Given that my wife has the ChatGPT app on her phone at the ready to answer any and all questions might mean that I may have completely missed the Borg assimilating my family.
My employer has also recognized that AI has arrived and in the interests of adapting to the new normal while continuing to be innovative, it has initiated several really cool projects involving artificial intelligence. A few years ago, I was present at a meeting where one of the first public releases of ChatGPT was discussed as well as other platforms that could generate images, audio, and video. The potential impacts on businesses were simultaneously fascinating, exciting, and terrifying. At the time, everything seemed like a hypothetical as there were no use cases to review to see the potential for use or regulatory frameworks in place to get an idea of the consequences of misuse. It truly was technology’s wild, wild west.
In 2025, all of those things are still being worked out, but there are use cases where AI has been effectively deployed, properly constrained, and ethically used. There have also been cases where it has been used for malevolent purposes or, in the case of the attorney who used it for his legal citations, been used while being willfully ignorant of AI’s limitations. When you’re dealing with technology that can imitate the human brain, you have to realize it can make mistakes the same way the human brain does. Just faster and at scale. To my employer’s great credit, they thoroughly examined the ethical and legal implications of using AI for work. As a result, when they looked for volunteers at an all-hands meeting to help wit these projects, I raised my hand.
I realized that I lacked experience with AI in almost every capacity, save for the occasional prompt typed into ChatGPT. I have written code before but that was for automating once manual tasks. I had gone through some online courses that taught how neural networks work with coding examples, so I at least understand machine learning at a basic conceptual level.
What I understand far better than machine learning is human learning. While I now work in a corporate environment, I have a degree in education and since I am dealing with a machine whose designers so desperately want it to appear human, I am going to approach my interactions with AI as I would an insanely smart child with very little life experience. The purpose of this blog is to document the installation, my interactions with the AI, and my observations on how it behaves. It’s a local installation not connected to the internet, so the information it can access, how much it learns, and how fast are, to a certain degree, up to me. As a result, I can look at what its baseline is and how it learns in detail.
That being said, please don’t construe this experiment as being remotely scientific in any way. I have no protocol developed and while I might formulate a plan on the fly, my interactions are most likely going to be driven by its responses to my prompts.
So let’s begin. My next entry will deal with installation and the initial conversation with my new officemate.